Architecture
Global Daemon¶
A single background process manages all registered repositories. Agents connect via POST /mcp and declare their target repo at session initialization. Session-based routing directs tool calls to the correct repo/worktree.
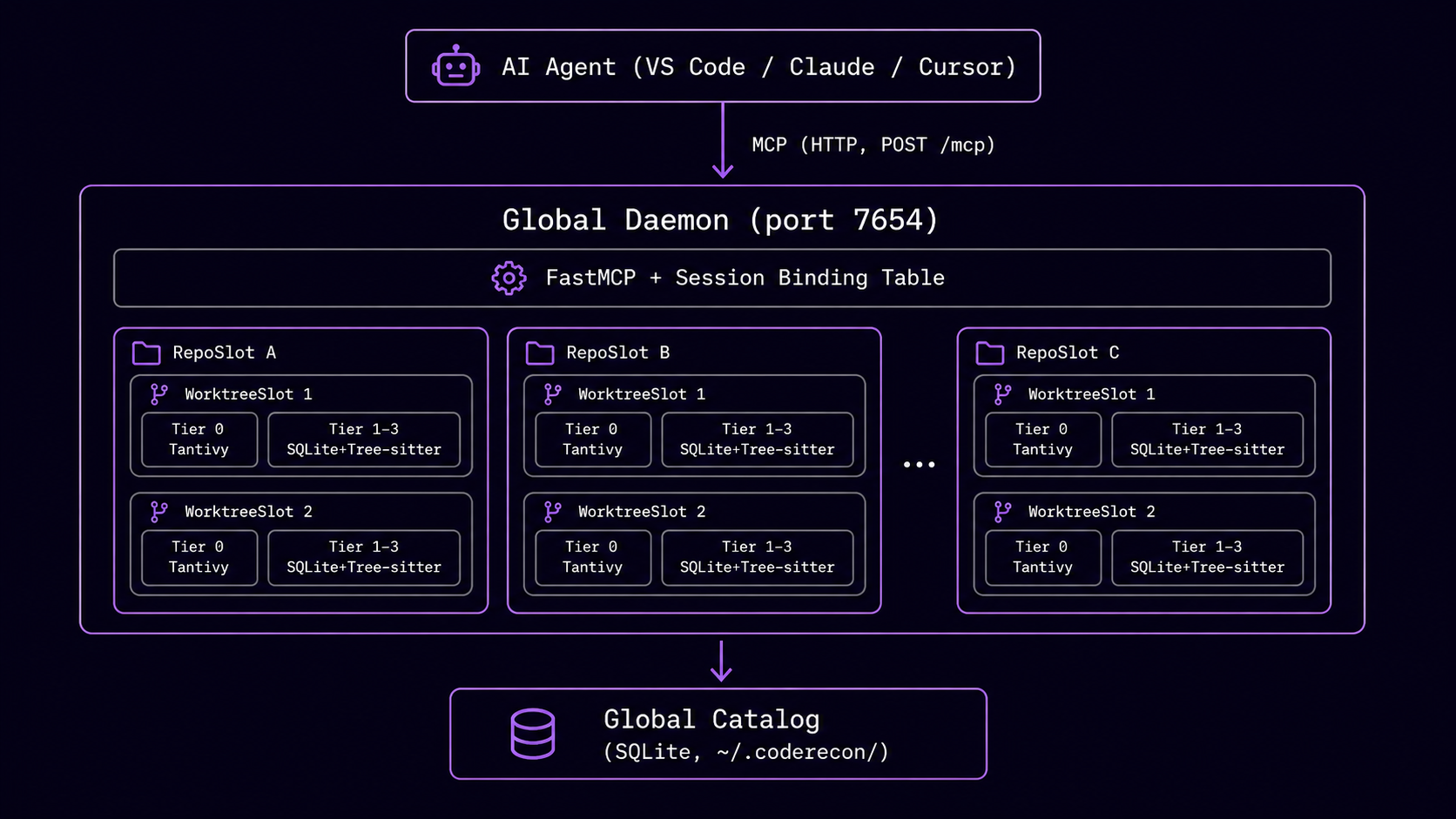
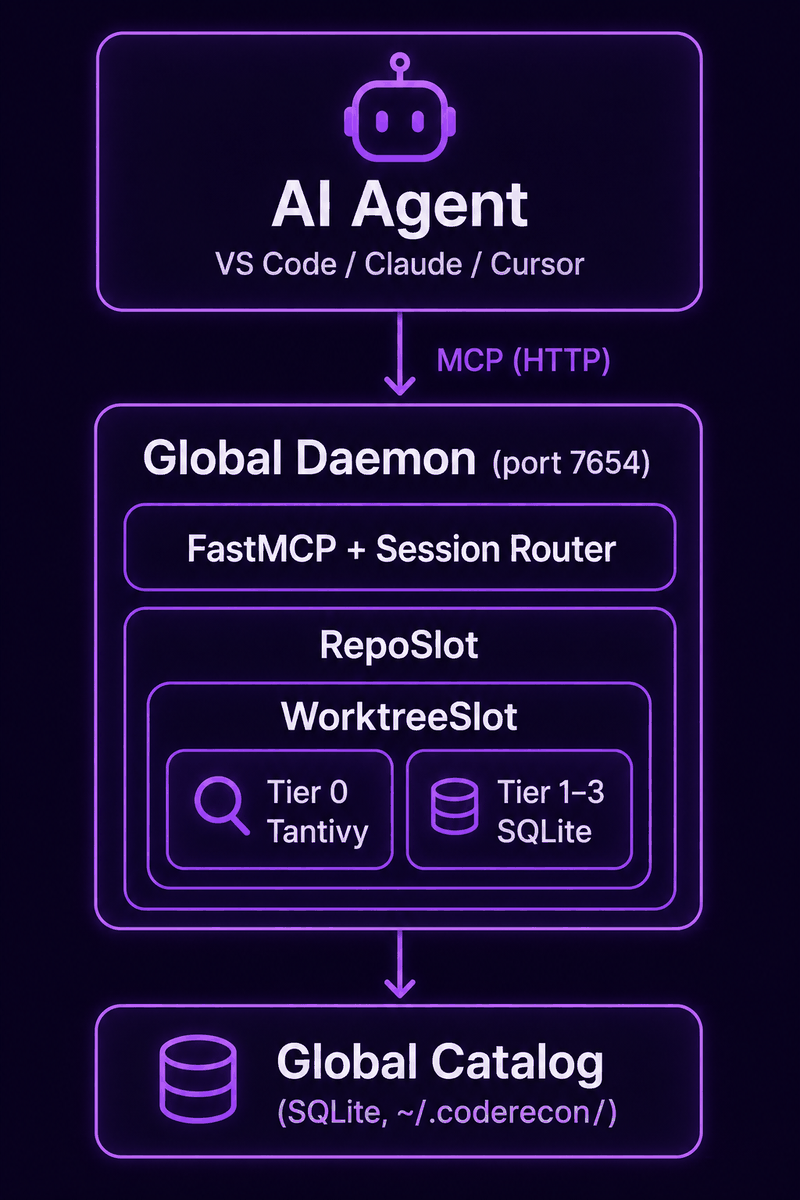
Four-Tier Index¶
Every registered repo builds and maintains a four-tier index inside .recon/.


Tier 0 — Lexical¶
Tantivy full-text index + per-definition scaffold index + SPLADE sparse vectors. Always on, kept fresh via file watcher.
Tier 1 — Structural (18 tables)¶
Tree-sitter parsed: DefFact, RefFact, ImportFact, ExportEntry, ScopeFact, LocalBindFact, and 12 supporting tables. The import graph drives graph_* tools and test selection.
Tier 2 — Type (5 tables)¶
Type annotations, type member chains, member access patterns, interface implementations, and receiver shape inference.
Tier 3 — Behavioral (11 tables)¶
Test coverage and reachability, call edges, per-line hit counts, lint status, doc cross-references, and SPLADE doc↔code semantic edges.
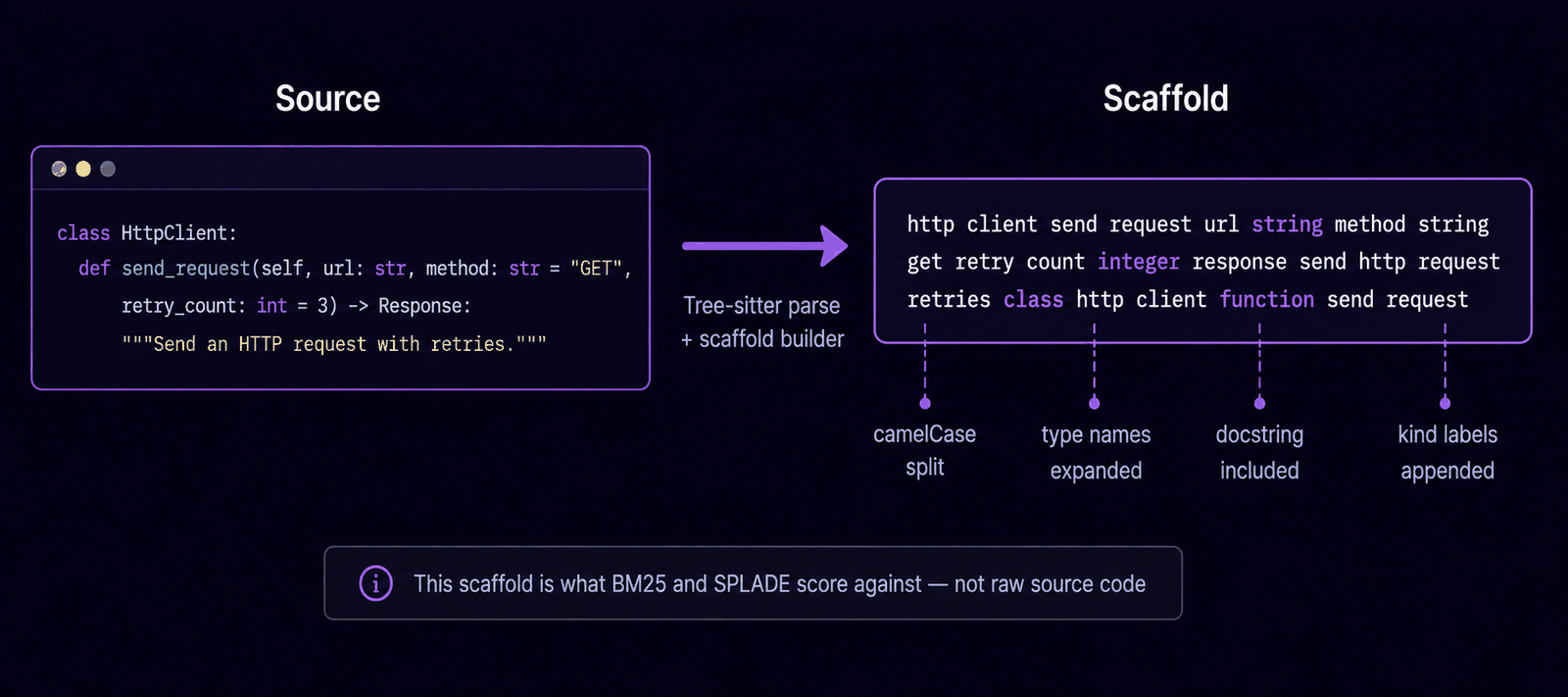
Scaffold: How Facts Become Searchable¶
Each definition is transformed into an anglicised scaffold — a flattened, tokenised summary. CamelCase split, type names expanded, docstrings included. This is what BM25 and SPLADE score against.

Ranking Pipeline¶
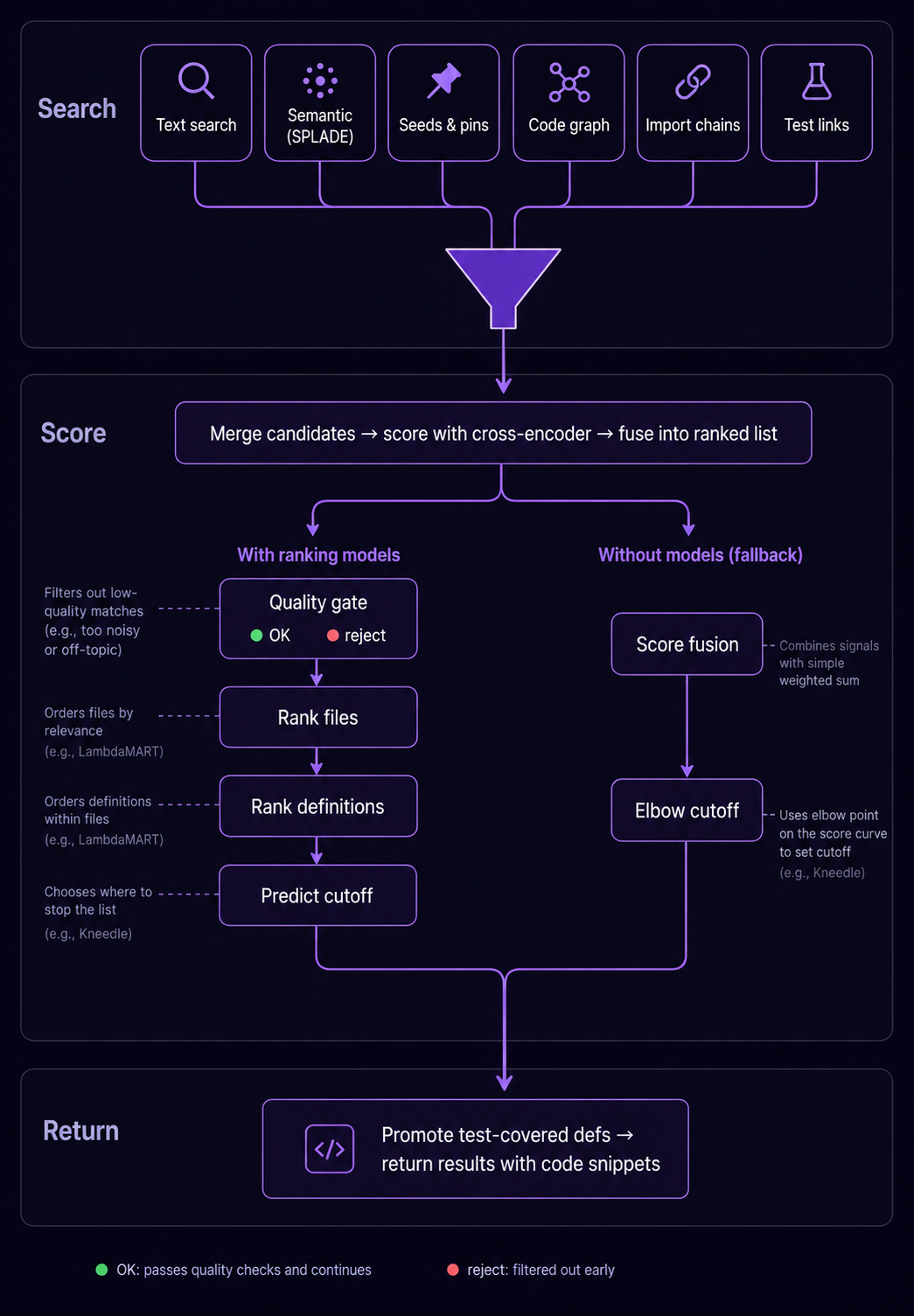
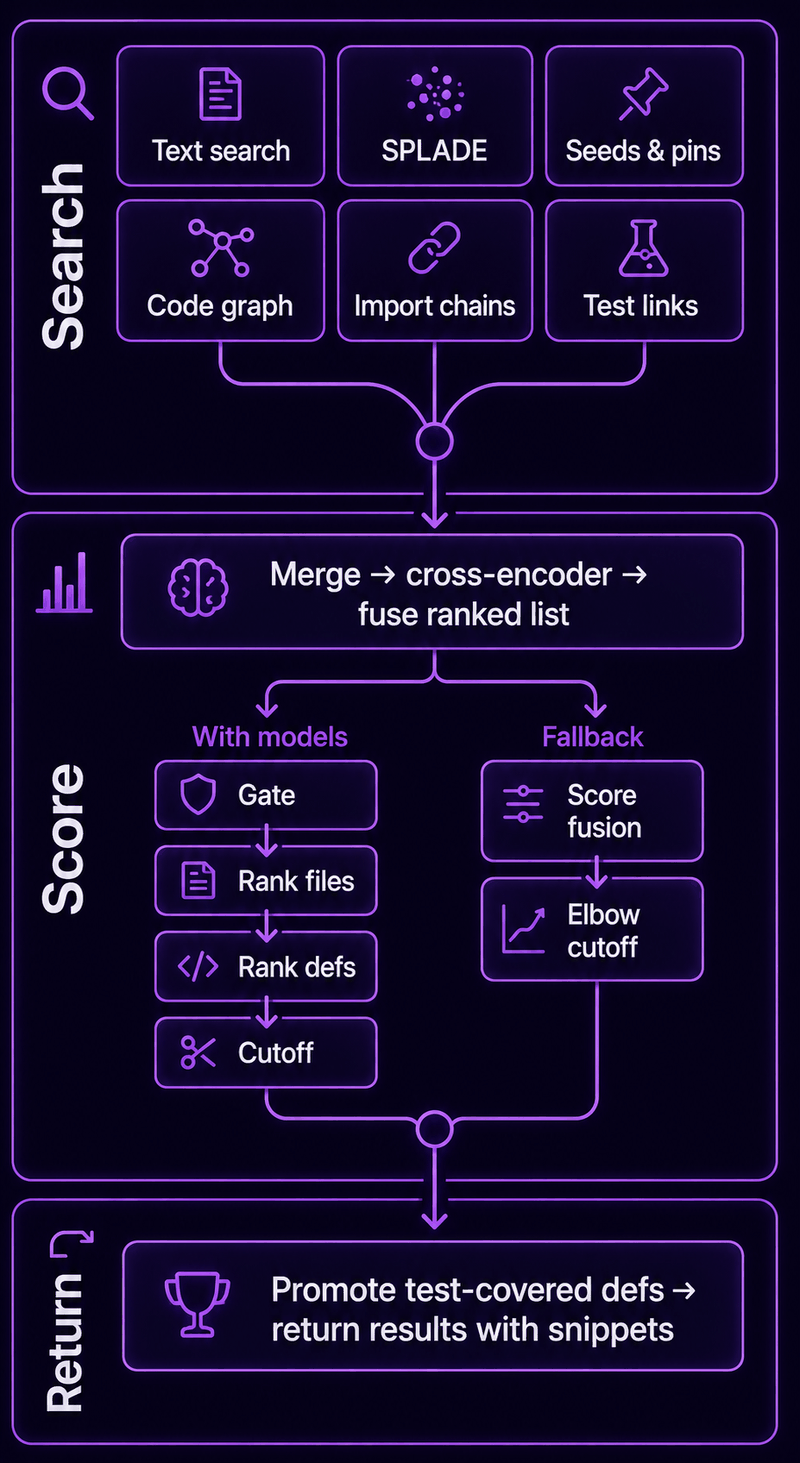
Six harvesters (BM25, SPLADE, seeds, graph walk, imports, coverage expansion) feed into a merge stage that also derives additional signals (hub score, retriever agreement, callee/importer of seed, shares-file). Cross-encoder reranking scores the merged pool, producing 11 rank lists + 6 continuous features for 17-list RRF fusion. If LightGBM models are available: gate → file ranker → def ranker → cutoff. Otherwise: RRF → elbow cutoff.
Freshness¶
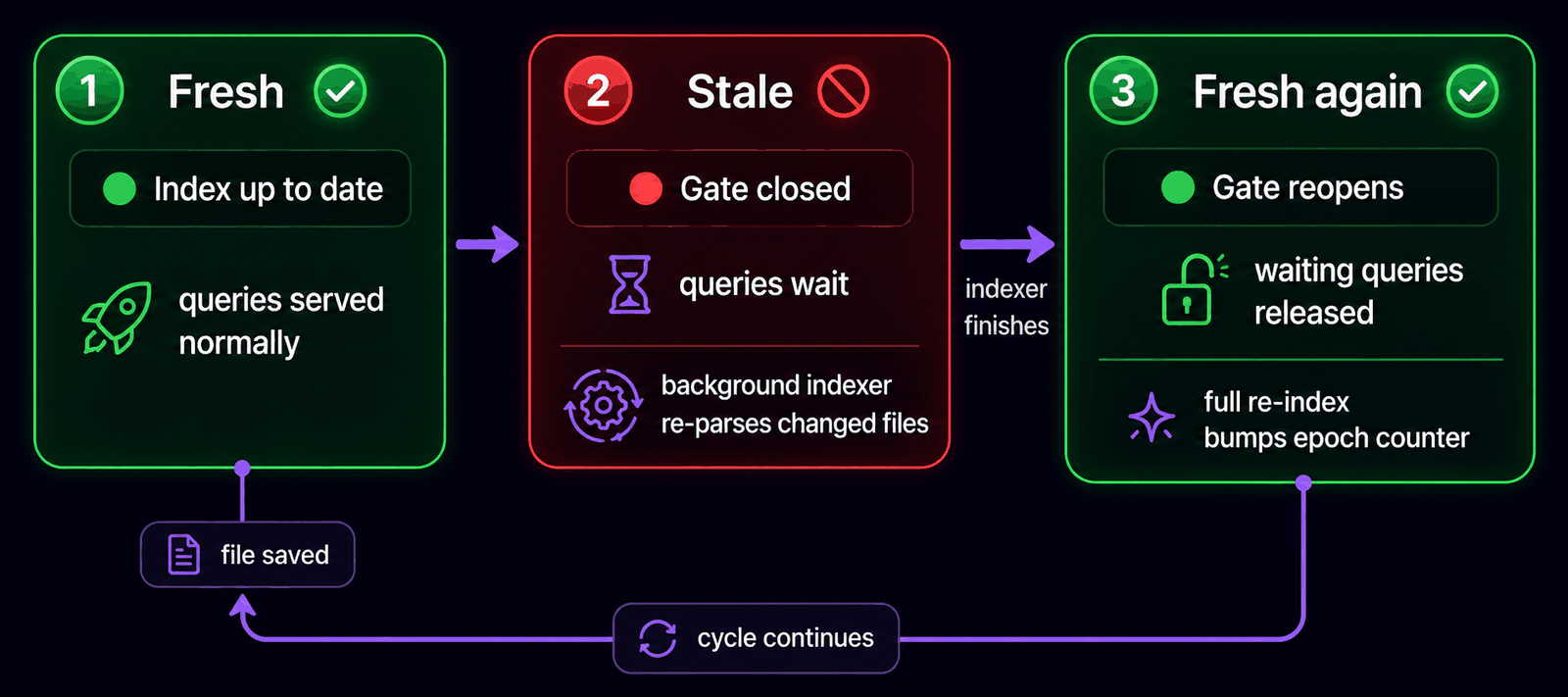
File edits mark the worktree stale. The background indexer processes deltas and reopens the gate. Queries wait for fresh. Full re-indexes bump the epoch counter.
Session Model¶
Each MCP connection gets an isolated session. Sessions hold:
candidate_maps— thereconcall's result, required before refactoringmutation_ctx— pending refactor IDs awaitingrefactor_commitorrefactor_cancelread_onlyflag — set viarecon(read_only=true)to block mutations
Sessions are scoped to a single agent conversation. No session state bleeds between connections.
Refactor Engine¶
Structural refactors (rename/move) are preview-first: the engine computes all edits and assigns each hunk a certainty level before any file is touched.
Certainty levels:
high — unambiguous symbol resolution
medium — probable match, context confirmed
low — possible match, human review suggested
When low-certainty hunks are present, refactor_commit returns a verification_required flag. The agent should use refactor_commit(inspect_path=...) to review those matches before applying.
The apply step runs inside a mutation lock to prevent concurrent conflicting changes.
Lint Subsystem¶
CodeRecon auto-detects and runs linters, formatters, and type checkers. The lint subsystem supports:
| Category | Examples |
|---|---|
| Lint | ruff, eslint, pylint, rubocop, phpcs |
| Format | black, prettier, gofmt, cargo fmt |
| Type check | mypy, tsc, go vet, cargo clippy |
| Security | (via linter security rules) |
Lint runs are triggered by checkpoint and can auto-fix issues before tests run.
Testing Subsystem¶
Test discovery and execution is handled by Runner Packs — language-specific plugins that detect, discover, run, and parse tests. Tests are not exposed as separate MCP tools; they are integrated into checkpoint.
Test selection uses the import graph:
| Hop | Description |
|---|---|
| 0 | Test files that directly import a changed file |
| 1 | Test files that import files that import a changed file |
| N | Further transitive dependencies |
By default, only hop-0 tests run. If hop-0 passes, hop-1 runs. If hop-0 fails, transitive hops are skipped. When a commit_message is provided, hop depth auto-escalates to 2 for broader coverage.
Worktree Support¶
CodeRecon supports Git worktrees. Each worktree is registered separately and gets its own entry in the global catalog. The index is shared (read-only) across worktrees; only the worktree-specific delta is tracked independently.
recon register-worktree # register current worktree
recon worktrees # list all worktrees for this repo
Cross-Filesystem Detection (WSL)¶
When a repo is on a Windows filesystem path (e.g. /mnt/c/...), cross-filesystem SQLite I/O would be prohibitively slow. CodeRecon detects this automatically at register time and moves the .recon/ index to a native Linux path: ~/.local/share/coderecon/indices/<repo-hash>/. This is transparent to the agent.
Containerized Environments¶
CodeRecon runs as a local Python process and inspects the host filesystem directly. When a project's runtime, dependencies, or configuration are abstracted away inside a Docker container or dev container, CodeRecon has no visibility into that environment.
Functionality that may be degraded:
- Dependency resolution — installed packages are read from the host Python environment, not the container's.
- Framework and runtime detection — version checks and feature detection rely on what is available locally.
- Test discovery — test runners and their plugins must be installed on the host for CodeRecon to detect and enumerate test targets.
- Language server / SCIP indexing — indexers run on the host and resolve imports against host-installed packages.
If your development workflow is fully containerized, consider running CodeRecon inside the container where the project environment is materialized, or ensure the host has a matching virtual environment.
File Watching and Delta Indexing¶
Once recon up starts the daemon, a file watcher monitors the repository for changes. When files are saved:
- Changed files are queued for re-parsing
- Tier 1–3 deltas are applied to SQLite
- Tantivy index is updated incrementally
This keeps the index fresh without requiring a full re-index between edits.
SDK¶
CodeRecon provides an async Python SDK for programmatic access. The SDK spawns the daemon over stdio (no port allocation needed) and exposes all MCP tools as typed async methods:
from coderecon.sdk import CodeRecon
async with CodeRecon() as cr:
await cr.register("/path/to/repo")
result = await cr.recon("my-repo", task="find auth logic")
The SDK also provides framework adapters:
as_openai_tools()— convert tools to OpenAI function-calling schemaas_langchain_tools()— convert tools to LangChain tool schema
See the SDK specification for wire protocol details.